We have developed a probabilistic generative model for phytoplankton communities. The proposed model takes counts of a set of phytoplankton taxa in a timeseries as its training data, and models communities by learning sparse co-occurrence structure between the taxa. Our model is probabilistic, where communities are represented by probability distributions over the species, and each time-step is represented by a probability distribution over the communities. The proposed approach uses a non-parametric, spatiotemporal topic model to encourage the communities to form an in- terpretable representation of the data, without making strong assumptions about the communities. We demonstrate the quality and interpretability of our method by its ability to improve performance of a simplistic regression model. We show that simple linear regression is sufficient to predict the community distribution learned by our method, and therefore the taxon distributions, from a set of naively chosen environment variables. In contrast, a similar regression model is insufficient to predict the taxon distributions directly or through PCA with the same level of accuracy.
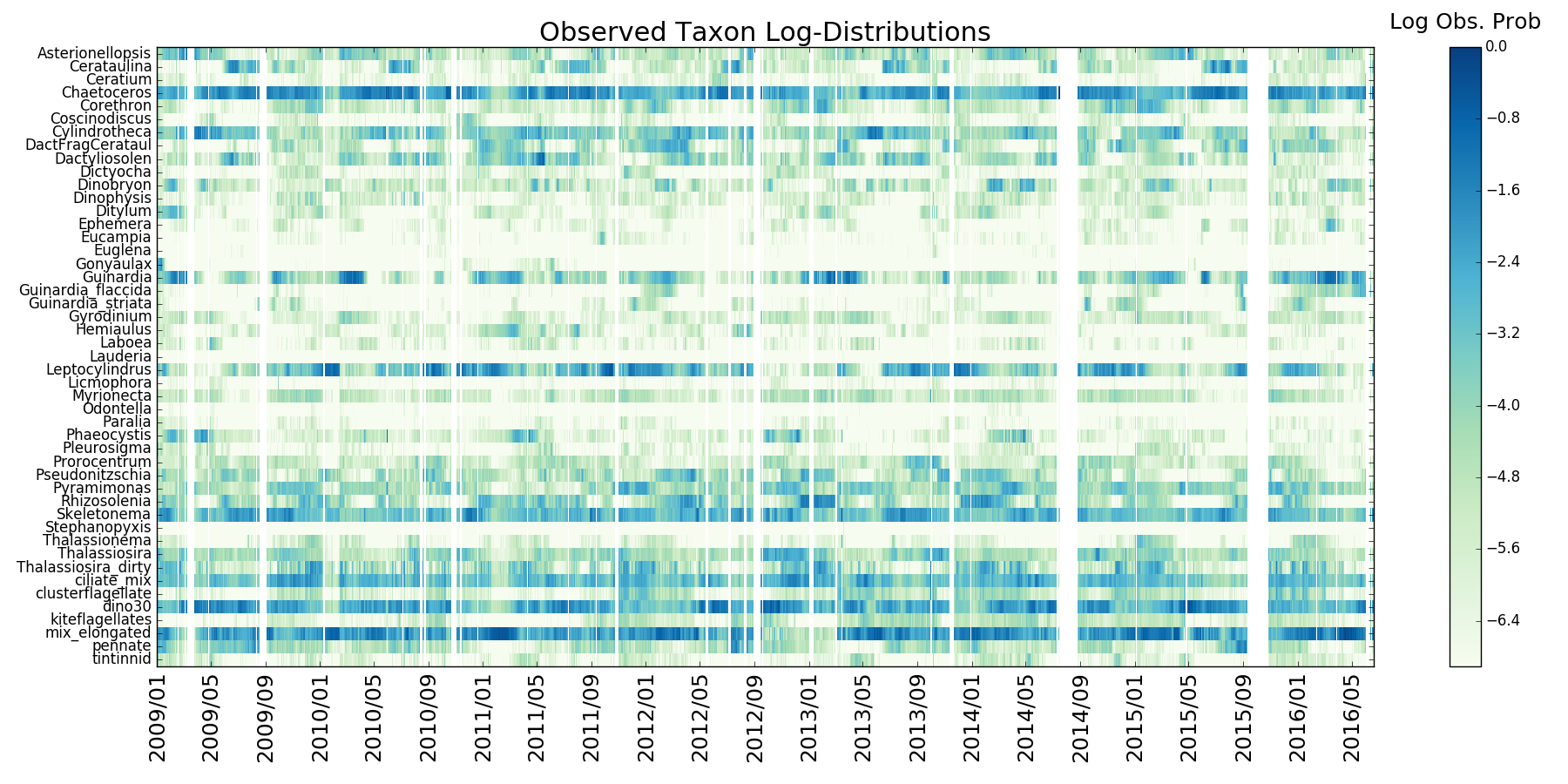
Observed phytoplankton taxon distribution from IFCB installed at MVCO:
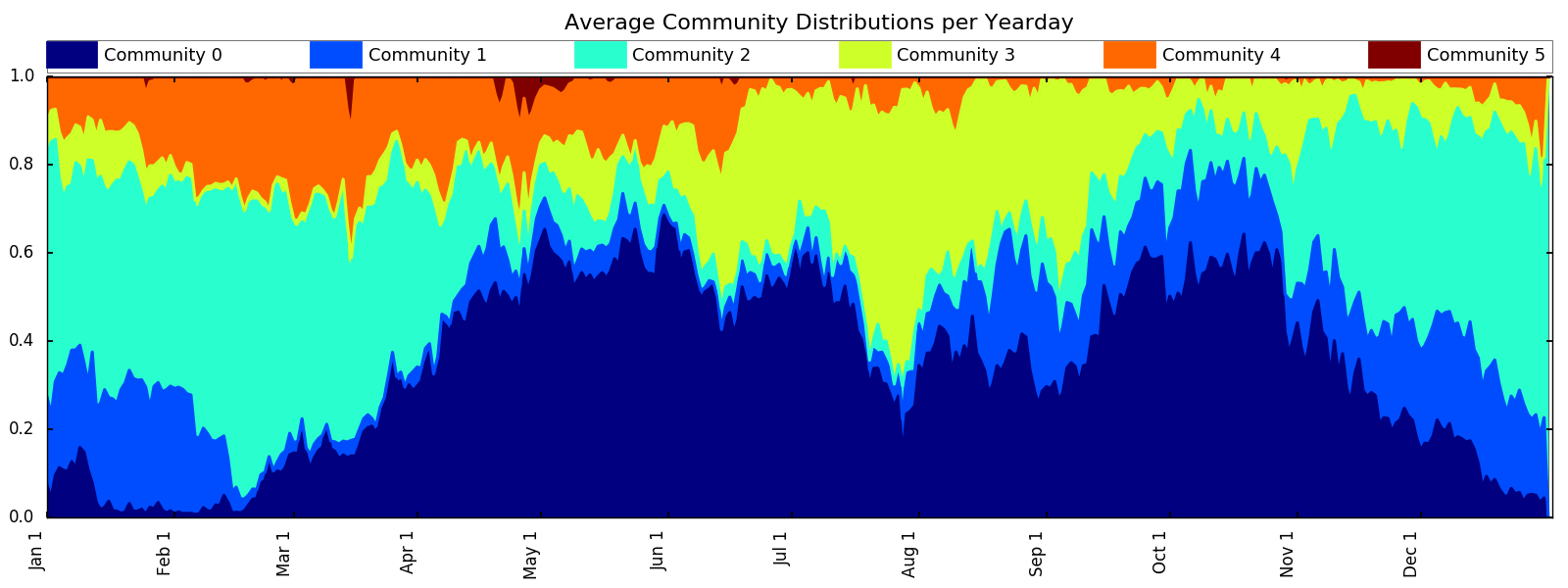
Seasonal distribution of communities:
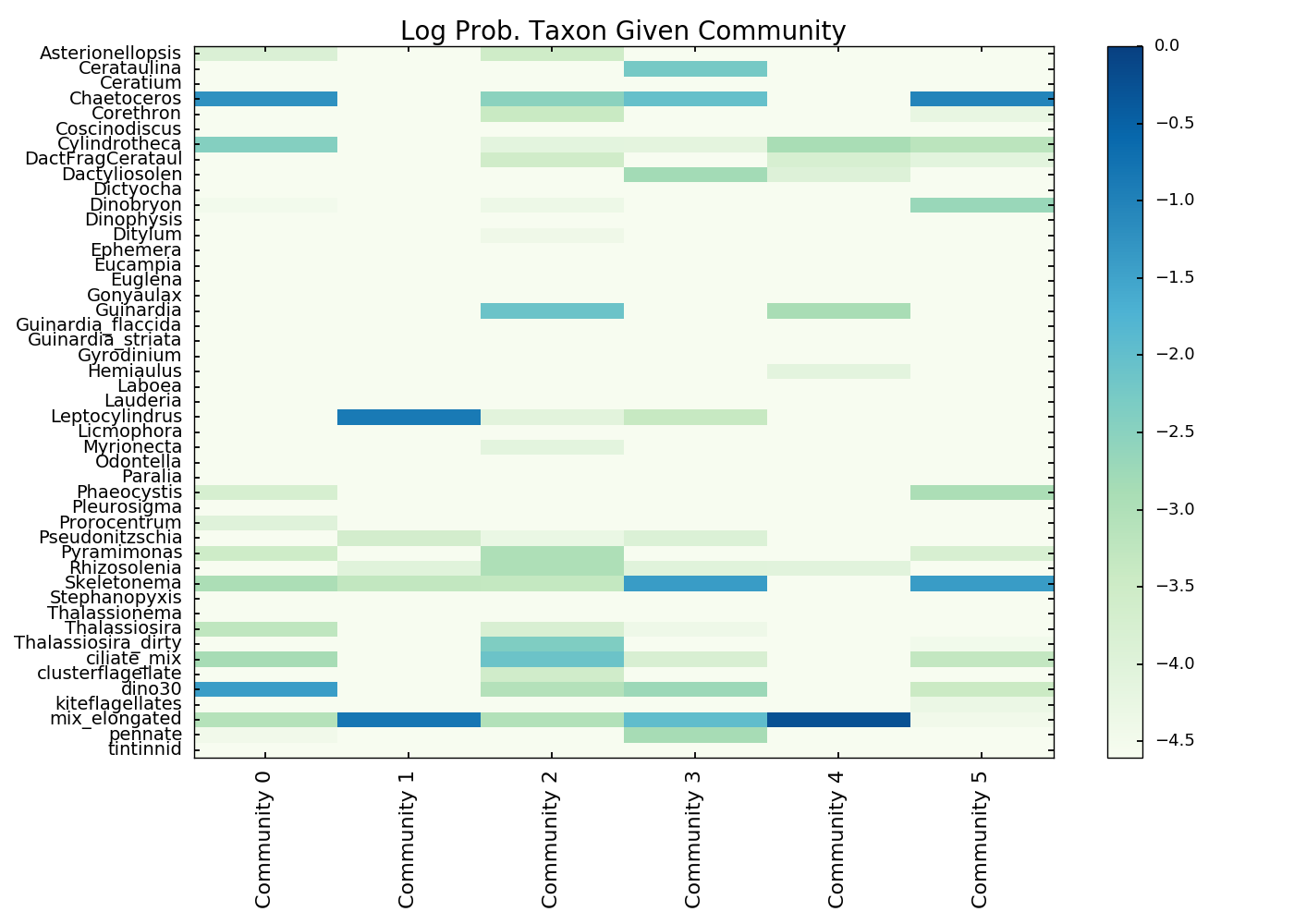
Each community described in terms of distribution over taxa:
More details available in our OCEANS paper.
